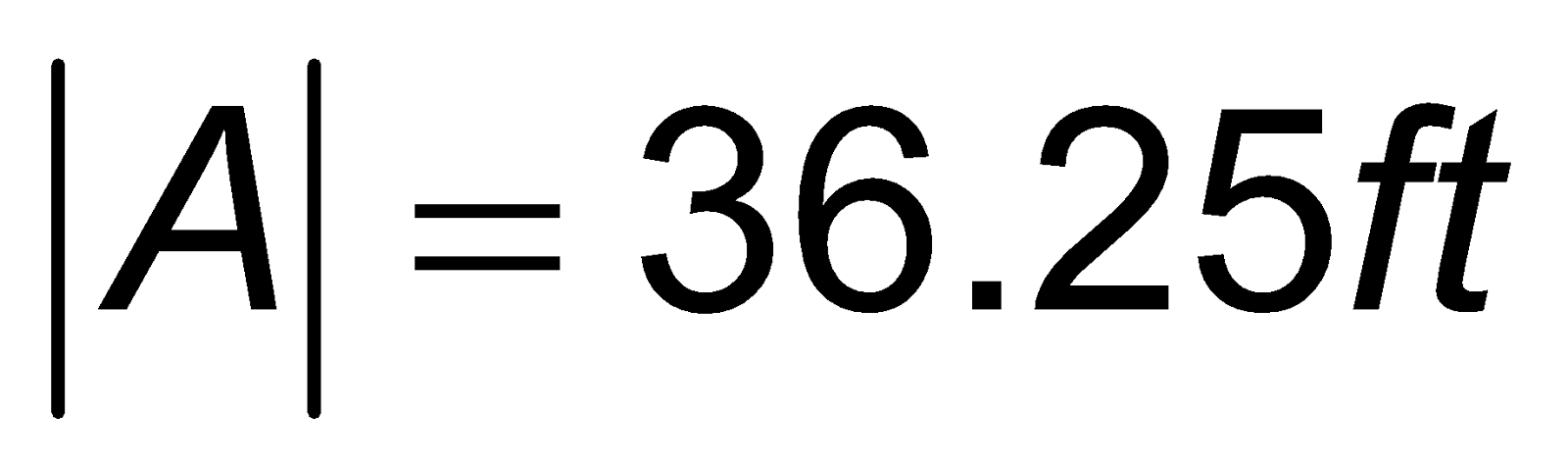Solution Found!
A small frog hops onto the Laxey wheel, a waterwheel in
Chapter , Problem 7.4.32(choose chapter or problem)
A small frog hops onto the Laxey wheel, a waterwheel in the Isle of Man, the largest in the world. Clinging to the wheel, the frog rides from its base, at a height of = 0 ft, to its top at a height of 72.5 ft, then back down. It rides the wheel once more before hopping off. Find a formula for = (), the frogs height above ground as a function of , the angle (in degrees), 90 630, and sketch its graph.
Questions & Answers
QUESTION:
A small frog hops onto the Laxey wheel, a waterwheel in the Isle of Man, the largest in the world. Clinging to the wheel, the frog rides from its base, at a height of = 0 ft, to its top at a height of 72.5 ft, then back down. It rides the wheel once more before hopping off. Find a formula for = (), the frogs height above ground as a function of , the angle (in degrees), 90 630, and sketch its graph.
ANSWER:Step 1 of 3
Consider that the maximum value of the frog at 
The minimum value of the frog at 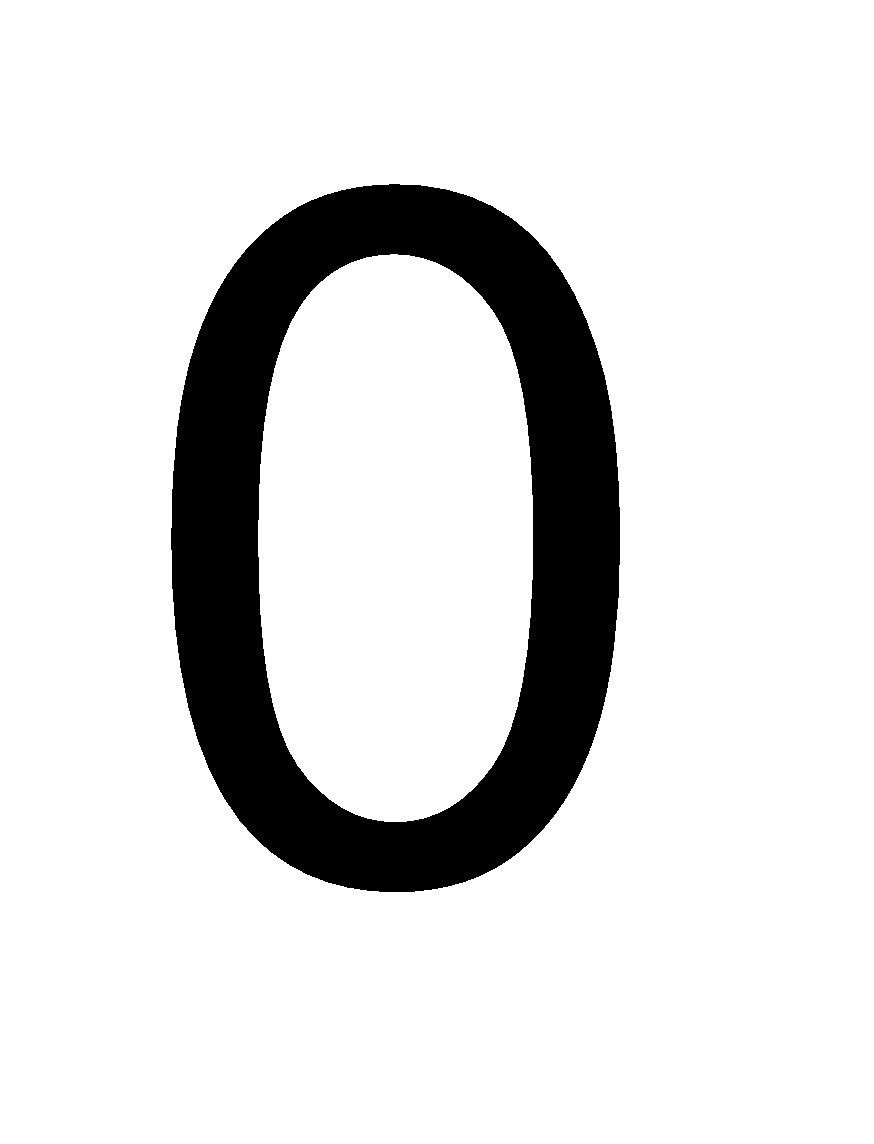
For, midline apply mid-point formula
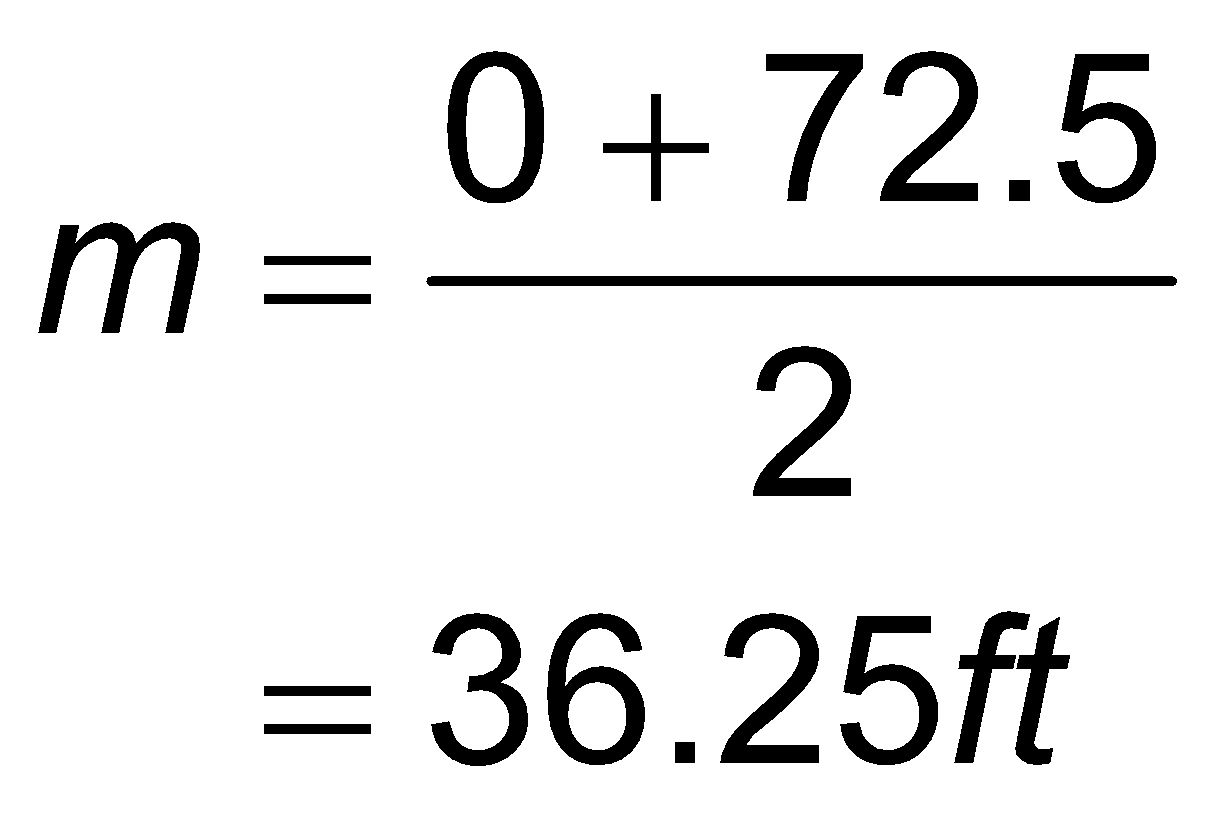
So, the amplitude is written as

The graph is sign function, because for sign maximum value occurred at 
Hence, the amplitude is